
Dummies Guide to Mechanistic Interpretability
Field Notes from the Gradient Frontier: Wrestling Dense Papers to Grok Mechanistic Interpretability
ChatGPT is everywhere. Every week, 500M+ people across the planet pour their hearts into it, ask it for dating advice, enlist its help on homework, and rely on it for all kinds of personal and professional questions. But most of us dont really understand how a machine can "think" - or whether it edges toward something like consciousness?
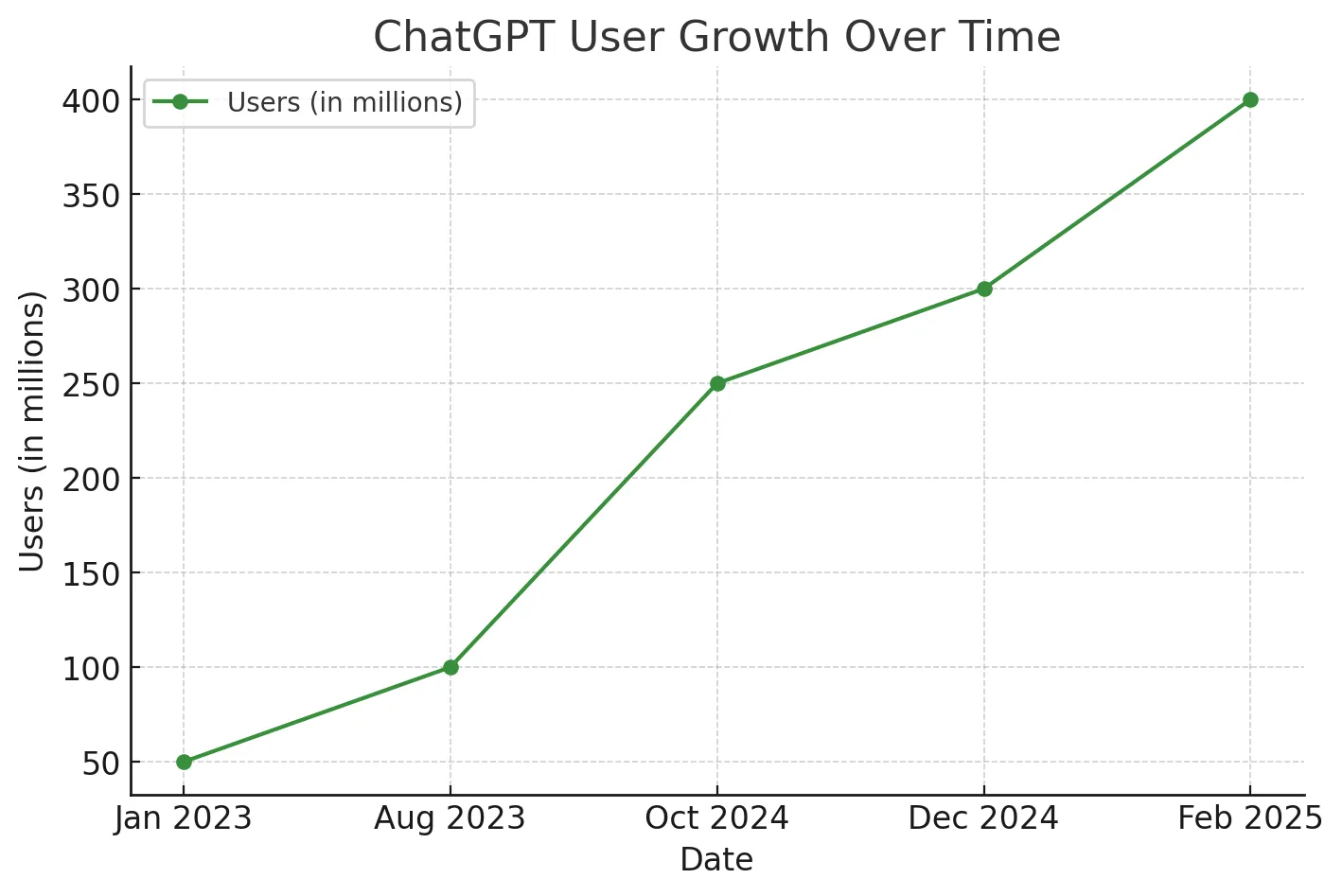
Behind that friendly chat interface is a staggering number of matrix multiplications - billions - solving linear algebra, trained on oceans of data, powered by processors originally designed to support high definition gaming, with a sprinkle of human feedback. Somehow, out of this concoction, a glimmer of reason and coherence emerges. The architecture of this thinking machine is loosely based on the human brain, and much like it, we don't fully understand how it is able to learn and perform cognitive tasks.
Mechanistic interpretability (MI) aims to open this "black box". It is a nascent field in AI that is trying to uncover how individual parts of a model interact to produce its outputs.
It's like the history of biology: for centuries, we've tried understanding how molecules become proteins, how proteins make cells, and how cells form conscious beings. AI seems to echo that process, but in digital form. MI is piecing together the building blocks of something that appears to reason, even if we're not entirely sure how. As someone who has always been curious about big existential questions - like why we're here and what consciousness even is - this new frontier of AI is especially exciting.
Philosophical pursuits aside, investing capital behind this problem also makes economic sense. The smartest people across critical industries today are using LLMs to help take decisions. But if they can't see inside this powerful tool, they can't fully control or even trust their outcomes. By building an output attribution system, MI aims to help steer and align LLMs towards human values.
Anthropic has done some of the most rigorous and forward-thinking work in mechanistic interpretability. While the field is still nascent, their research has consistently pushed the boundaries of how we understand what's happening inside large language models. The three papers below form the foundation of my understanding of this space - each building on the last, and together offering a compelling narrative of how we might one day read and even steer the thoughts of machines.
1. Toy Models of Superposition (2022)
Basics of Neural Networks
A neural network starts with an input - such as an image or a sentence - and processes it through one or more layers of interconnected "neurons." A neuron can be thought of as a small computational unit.
Each neuron computes a simple function: it applies a linear transformation (multiplying the input by certain "weights") followed by a nonlinear activation (like a ReLU or sigmoid). Stacking these neurons into multiple layers allows the network to gradually transform raw data into higher-level "features" or concepts.
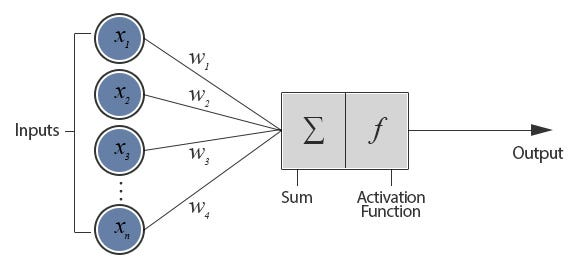
For smaller models, it's sometimes possible to identify a direct link between a single neuron and a distinct concept. However, as the number of neurons grows into the thousands, neural networks develop more complex internal representations. In practice, researchers have observed that while some neurons cleanly map to individual features, this doesn't hold for many of the neurons in large-scale models - particularly in large language models (LLMs).
The paper "Toy Models of Superposition" examines why and how these large networks often represent more features than they have neurons. This phenomenon is called superposition, where multiple concepts can be encoded in a single neuron. The paper employs smaller, more tractable "toy" networks to illustrate this phenomenon and explore how and why it happens.
Key Takeaways
-
Superposition Is Real
Networks (neural patterns) do, in fact, compress multiple features into fewer neurons. This is an efficient but complex way for them to store information.
-
Monosemantic vs. Polysemantic Neurons
- Monosemantic neurons capture a single feature cleanly.
- Polysemantic neurons activate for multiple unrelated features, reflecting the network's inclination to use every bit of representational space as efficiently as possible.
Understanding Superposition:
In a neural network, each layer represents information as a vector - a list of numbers. The length of this vector defines how many dimensions the model has at that layer to store what it knows. You can think of each dimension as a neuron or a representational axis.
But here's the twist: large language models (LLMs) often learn more features than they have dimensions to store them. This is called superposition (Schrodinger's Cat anyone?)

Instead of assigning one neuron to one idea (like "cat" or "not cat"), the network cleverly overlaps many features in the same representational space. It learns to compress multiple abstract patterns into a shared set of neurons - and this isn't a mistake. It's just efficient.
Neural networks are optimized to use their representational space well. If squishing multiple features into one neuron reduces cost without hurting performance, they'll do it. And as it turns out, they do it all the time.
In Toy Models of Superposition, the authors construct small networks where they can observe exactly what's going on under the hood. Their key findings:
- The network stores more features than it has neurons to store them.
- Some neurons are monosemantic - they activate for a single, interpretable feature.
- But many are polysemantic - they activate for multiple unrelated features, depending on context.
Who programs Superposition?
Superposition happens naturally. It is not programmed into the network - it's an emergent property that arises as a side effect of how we train neural networks.
Neural networks are trained using "gradient descent" - a process that optimizes for performance, not interpretability. The goal is to minimize prediction error, not to make internal representations clean or human-readable.
So during training:
- If the network can perform better by storing multiple useful features in a single neuron, it will.
- If there's a bottleneck (fewer neurons than features), it learns to pack information more densely.
- If there's redundancy across features, it learns to reuse dimensions efficiently.
This behavior - compressing multiple features into fewer dimensions - is simply what optimization under resource constraints looks like.
How do we make sense of Superposition?
Described three strategies to finding a sparse and interpretable set of features if they are indeed hidden by superposition:
(1) creating models without superposition, perhaps by encouraging activation sparsity;
(2) using dictionary learning to find an over-complete feature basis in a model exhibiting superposition; and
(3) hybrid approaches relying on a combination of the two.
This makes way for the next seminal paper:
2. Towards Monosemanticity
Toy Models of Superposition gave us the core challenge with interpreting language models: superposition. Models try to represent more ideas than they have room for. So they compress.
Towards Monosemanticity offers a concrete way forward.
Key Takeaways from this paper:
-
SAEs offer a results-worthy path to interpret models.
They extract clean, often monosemantic features from messy activation patterns - making internal reasoning visible and understandable.
-
The features are real and generalizable.
The SAEs are also picking up features that were not in the training set of the SAEs. This is very important as it shows that the method is generalizable.
-
Scaling reveals sharper structure.
Bigger autoencoders don't just find more features - they split broad ones into finer, interpretable components. Maybe we have a new scaling law?
-
Small models hide surprising capacity.
Even a 512-neuron model can represent tens of thousands of features through compression.
-
Features show up across different models.
When you train sparse autoencoders on different language models, you get similar features. This suggests these aren't quirks of a specific model — they reflect something fundamental about how language models represent ideas.
Experimentation Set Up
The authors focus on one of the smallest models that still exhibits this problem: a language model with just one layer and 512 neurons per word. For context, GPT-4o - the version of ChatGPT you're likely using - has around 100 layers and tens of thousands of neurons working together to process each token. So this one-layer model is tiny by today's standards.
And yet, even in this stripped-down version, we can't easily tell what's going on inside. Even here, a single neuron might be doing ten different things. The goal of this paper is to crack open that internal activity - to break down each neuron's messy signal into clean, understandable components, each tied to a specific, human-recognizable pattern.
In order to "decompose" a model's thinking, the team also designing models with extremely sparse activations - even going so far as to allow only one neuron to fire at a time. Technically, this should have eliminated superposition. But it didn't solve the deeper problem: the way these models are trained - minimizing the difference between their predicted output and the correct one - still rewarded neurons that carried multiple meanings. Even when the architecture was built for clean reasoning, the training objective silently preferred ambiguity. Turns out, if cramming a few unrelated features into one neuron helps the model get better test scores, that's what it'll do.
Enter Sparse Auto Encoders
An encoder is anything that compresses information. A decoder is what reconstructs it back. For example:
- ZIP files: Our computers encode a bunch of files into a compressed archive, and decode it when we open it.
- JPEGs: Our phones encode photos to reduce size - the decoder lets us view them.
- Spotify: Audio is compressed and streamed, then decoded for playback.
In all of these, the encoder tries to keep what matters and throw away the rest. The decoder does its best to reconstruct the original, using just that compressed form.
Autoencoders are neural networks trained to do the same thing - but learned from data.
- The encoder takes an input (say, an image or a vector from a language model) and compresses it into a smaller internal code.
- The decoder takes that code and tries to reconstruct the original input.
If the model learns to do this well, it must have captured the core patterns of the data — not surface noise.
Autoencoders are widely used in things like Image denoising (removing blur or grain) or Anomaly detection (spotting fraud, system failures, etc.)
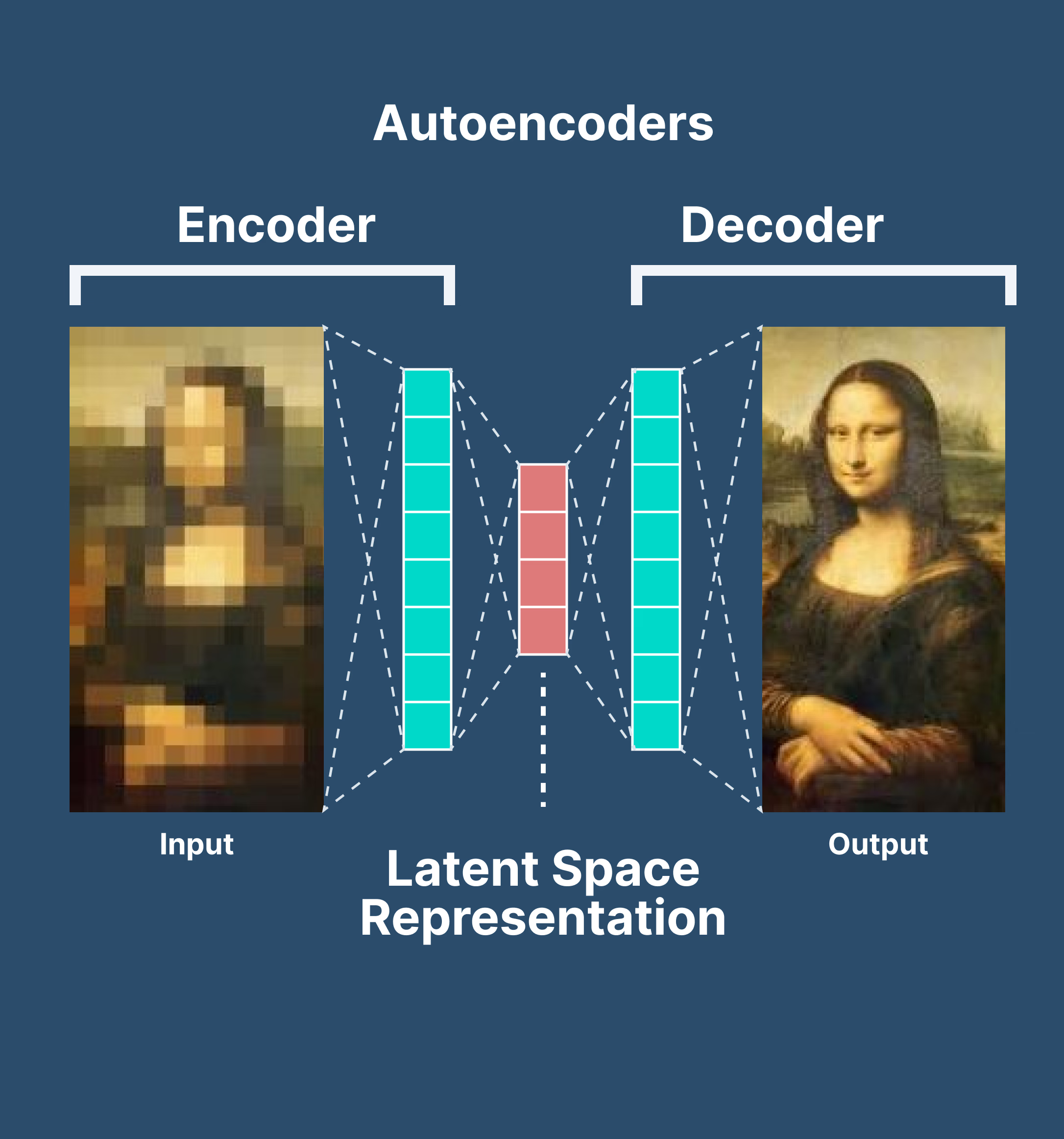
"Sparse" Auto Encoders?
In regular autoencoders, the encoder might activate all features for every input. That works — but it's messy. A sparse autoencoder forces the model to only activate a few features at a time.
This is exactly what we want when we're trying to interpret a model's internal state. Sparse features are easier to name, track, and intervene on.
How Do We Train a Sparse Autoencoder?
To train a Sparse Autoencoder (SAE), we don't need new data - we need access to what the language model is already doing internally. Specifically, you collect the activation vectors from the model's hidden layers while it processes normal language inputs.
We take a pretrained language model and run it on a large dataset. As the model processes each token, it computes internal activations at every layer. For each token, we extract that activation vector (say, a 512-dimensional vector), and save it. This is our training data.
So we're not labeling anything. We're not asking the model to do anything special. We're simply running it as-is on raw text, and recording the internal activations.

So, training works like any other neural network:
- We give it an input (e.g. a 512-dimensional vector from a model).
- The encoder compresses it into a larger-but-sparse feature vector (say, 4,096 features, but only 20 are active).
- The decoder tries to reconstruct the original 512-vector using just those sparse activations.
- The model is penalized for two things:
- Reconstruction error: How far off it is from the original.
- Too many active features: Encouraging sparsity.
Over time, the autoencoder learns:
- A set of clean feature directions (via the decoder)
- A sparse encoding scheme that only activates what matters (via the encoder)
When applied to neural network internals SAEs give us:
- A way to see what concepts or features are active
- A method to intervene and steer behavior
- A cleaner, compressed language to describe what the model is doing
How does a SAE work with a Language Model?
When we input a prompt into a language model - say, "Generate a legal disclaimer in Arabic" - the model processes it token by token, constructing internal representations at each step. At every layer, it forms activation vectors: dense, high-dimensional snapshots of what the model is "thinking" about each token in context. A token like "legal", for instance, might yield a 512-dimensional vector capturing nuances such as tone, formality, domain-specific structure, and more.
This is where Sparse Autoencoders (SAEs) enter - not embedded inside the model, but operating alongside it. The SAE takes these dense activations and runs them through an encoder, expanding the signal into a much larger set of features - say 4,096 - but crucially, activating only a small, sparse subset. Each active feature corresponds to an interpretable concept the SAE has discovered. Rather than just observing that some neuron lit up, we can start to say things like:
"The model appears to be thinking in terms of 'legal language' and 'Arabic script.'" The decoder can even reconstruct the original activation from just this small set, confirming that the sparse features carry meaningful, information-rich content.
This capability doesn't emerge magically. SAEs are trained on billions of activation vectors drawn from across many model prompts. Over time, they learn to disentangle the chaotic, overlapping signals present in dense activations and re-represent them as clean, modular, human-interpretable concepts.
3. Scaling Monosemanticity
In Towards Monosemanticity, Anthropic showed that sparse autoencoders could pull clean, interpretable features from a toy one-layer transformer. That was a proof of concept - valuable, but still in lab like conditions. The obvious next question was: can this scale? Could this technique make sense of real, production-scale models? Or would it break under the weight of modern complexity? In Scaling Monosemanticity, they successfully apply sparse autoencoders to Claude 3 Sonnet - a commercial-grade model orders of magnitude larger than the original setup. And the method still works.

Key Takeaways:
-
Sparse autoencoders scale to production-grade models.
What worked on a toy 1-layer model now works on Claude 3 Sonnet - a real, medium-sized language model used in the wild. This validates that monosemantic interpretability isn't just an academic trick; it's a viable tool for understanding actual deployed systems.
-
High-quality, abstract features emerge.
The autoencoder surfaces features tied to recognizable concepts: famous people, cities, countries, programming patterns, and more. These aren't fuzzy or partial - many are sharp, human-interpretable, and consistent across inputs.
-
Features generalize across languages and modalities.
Some features fire for the same concept in multiple languages and across text and images. That means these aren't shallow keyword triggers - they reflect deep, underlying representations the model has learned.

-
Features capture both concrete examples and abstract ideas.
For instance, one feature fires for actual insecure code, and also for abstract writing about security. This ability to unify different forms of the same idea suggests these features are tapping into real model reasoning - not surface correlations.
-
You can use these features to steer the model.
Activating a feature can cause the model to behave in line with that concept — e.g., generating text about a particular topic. This makes the features actionable, not just descriptive - a step toward controllability.
Conclusion
Mechanistic interpretability is one of the most quietly important fields in AI today - yet barely anyone outside a small community is paying attention. Most people are still focused on building faster, bigger models. More layers, more data, more compute. But many of the most thoughtful researchers already suspect that true leaps - toward something like AGI - won't come from scaling alone. Not from another round of parameter inflation, or another clever workflow like chain-of-thought or Mixture-of-Experts. If that future arrives, it will come from an architectural breakthrough - something that fundamentally changes how models represent, reason, and generalize.
Interpretability might be the first real glimpse of that shift.
Sparse autoencoders and feature-based decomposition are early tools - they're beginning to peel back the layers of black-box models and show us that meaning isn't just emerging - it's structured.
That's profound. Not just for aligning AI with human intent, but for understanding how intelligent systems think at all. In fact, this work might not just be about machines. It might be a mirror.
For the first time in history, we can run live experiments on complex, high-dimensional "brains" that are learning, adapting, and compressing knowledge - without needing ethics boards or microscopes. We've never had this kind of substrate before. This might be our way to do neuroscience in silico - to study how learning and abstraction emerge, not just in silicon, but maybe in ourselves.